面向多星多任務的大數據處理系統設計
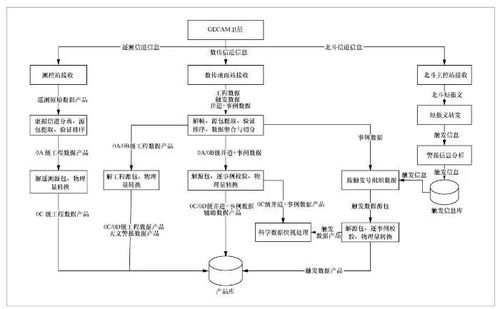
隨著航天技術的飛速發展,全球在軌衛星數量急劇增加,遙感觀測、氣象監測、通信導航等各類航天任務產生了海量、多源、異構的觀測數據。如何高效、可靠地處理這些來自多顆衛星、服務于多類任務的海量數據,已成為航天測控、遙感應用等領域面臨的核心挑戰。構建一個面向多星多任務的大數據處理系統,是實現數據價值最大化、提升任務響應能力的關鍵。
一、 系統設計的核心挑戰
- 數據海量與異構性:多顆衛星(如光學、雷達、高光譜、氣象衛星)產生的數據格式、分辨率、時相各不相同,數據體量呈指數級增長,傳統處理架構難以應對。
- 任務多樣性與實時性要求:系統需同時支撐科學研究、災害應急、國防安全、商業服務等不同任務,其對數據處理的時效性、精度和產品類型要求各異。
- 資源動態調度與協同:計算、存儲、網絡資源需要在多個并發任務間高效、彈性地分配,確保高優先級任務(如災害應急)能得到即時保障。
- 系統可靠性與可擴展性:需滿足7x24小時不間斷運行,并能平滑擴展以容納未來新的衛星、傳感器和任務需求。
二、 系統總體架構設計
一個典型的面向多星多任務的大數據處理系統通常采用分層、微服務化的云原生架構,以實現松耦合、高內聚和彈性伸縮。
1. 數據接入與管理層
- 多源接入:通過地面站網、數據中繼衛星等渠道,接收來自不同衛星的原始數據流。
- 統一編目與存儲:對原始數據、中間數據和最終產品進行標準化描述與元數據管理,并利用分布式對象存儲(如HDFS、Ceph)或云存儲服務進行持久化,形成數據湖。
2. 分布式計算處理層(核心)
- 計算框架:采用批流融合的大數據計算框架,如Apache Spark(批處理)、Apache Flink(流處理),以應對歷史數據回溯分析和實時數據流處理。
- 任務調度與編排:引入Kubernetes等容器編排工具,配合自定義的任務調度器。調度器能根據任務類型(CPU密集型如正射校正、GPU密集型如目標識別)、優先級、數據局部性和資源狀態,動態地將處理任務分解并調度到計算集群的各個節點上。
- 算法容器化:將輻射定標、大氣校正、圖像融合、信息提取等各類處理算法封裝為獨立的Docker容器,實現算法的解耦、復用和敏捷部署。
3. 智能服務與協同層
- 服務化接口:通過RESTful API或消息隊列,向上層應用(如WebGIS平臺、移動應用、專業分析工具)提供標準化的數據查詢、訂閱、處理任務提交和產品獲取服務。
- 工作流引擎:對于復雜的多步驟處理任務(如“數據獲取->預處理->變化檢測->報告生成”),采用工作流引擎(如Apache Airflow)進行可視化編排與自動化執行。
- 數據與知識協同:引入數據倉庫或知識圖譜技術,對多源數據進行關聯、融合與深度挖掘,形成更高層次的態勢信息和知識,支撐智能決策。
4. 資源監控與運維層
- 全景監控:對集群的CPU、內存、存儲、網絡IO以及各類任務的狀態、進度、性能進行實時監控與可視化。
- 彈性伸縮:基于監控指標和任務隊列負載,自動觸發計算資源的擴縮容,實現成本與效率的最優平衡。
三、 關鍵技術與創新點
- 異構計算資源統一池化:整合CPU、GPU、FPGA等異構計算資源,通過虛擬化或容器化技術形成統一資源池,使不同類型的數據處理任務能調度到最適合的硬件上執行。
- 基于優先級和公平性的動態調度策略:設計混合調度策略,既保證災害應急等高優先級任務的即時搶占式處理,又通過隊列、權重等機制保障科研等長周期任務的公平性與進展。
- 存算分離與數據本地化優化:采用存算分離架構提升系統彈性,同時通過智能緩存、數據預取和計算任務調度至數據所在節點附近,最大限度減少數據網絡傳輸開銷。
- AI賦能的數據智能處理:集成機器學習、深度學習框架(如TensorFlow, PyTorch),將AI模型用于數據質量自動控制、智能壓縮、特征自動提取與分類、異常檢測等環節,提升處理的自動化與智能化水平。
四、 與展望
面向多星多任務的大數據處理系統,其核心思想是以數據為中心,以服務為導向,以智能為驅動。通過構建云原生、微服務化的彈性架構,并深度融合大數據與人工智能技術,該系統能夠有效應對數據洪流,靈活服務多元任務,最終將海量衛星數據高效轉化為精準、及時、可用的信息和知識。
隨著星上計算、邊緣計算技術的發展,數據處理將進一步向“星-地-云”協同的泛在計算模式演進。區塊鏈等技術可能在數據確權、交易與安全共享方面為系統帶來新的維度。系統設計需保持前瞻性和開放性,以持續適應航天大數據領域日新月異的發展需求。
如若轉載,請注明出處:http://m.wadru.cn/product/81.html
更新時間:2026-02-21 04:47:08